Micromed EEG
This is a journal of how I reversed engineered a file format, and a viewer for Microsoft Windows. The end result is the NeuroLab project, along with an ISO C library libvwr, both freely available and open source.
Enjoy.
Abstract
Neurology makes use of several tests, among them, the Electroencephalography (EEG). It consists of several electrodes that are connected to the scalp of the patient, and the machine records a time-dependent signal corresponding to the difference of potential between two electrodes.
Among the manufacturers of EEG machines, we have Micromed.
This practical problem arose from the fact that there is no viewer outside Microsoft Windows for their file format, VWR. I needed a viewer because I've seen my wife not being able to open their files on her Apple laptop. Apart from personal reasons, it was a while since I worked in assembly and reverse engineered binaries. It sounded like fun, and it was fun.
Hence, in order to visualize on macOS their EEGs, I needed to start from scratch. Reverse engineering a file format requires at least to have a program that can be run. Otherwise I had to do a lot of guesswork, and medical records do not mix with guesswork. Fortunately, I had their SystemViewer98 application, whose name already promises to be fun to be reverse engineered.
Here I will guide you through the process of reverse engineering a file format. The end result is a viewer, NeuroLab, published online for free.
Legal disclaimer. This project is intended as reverse engineering with the sole purpose of system interoperability, and it is protected under the law (L. 633/41 Art. 64, 22 April 1941, n. 633; L. 518/92 Art. 5, 29 December 1992).
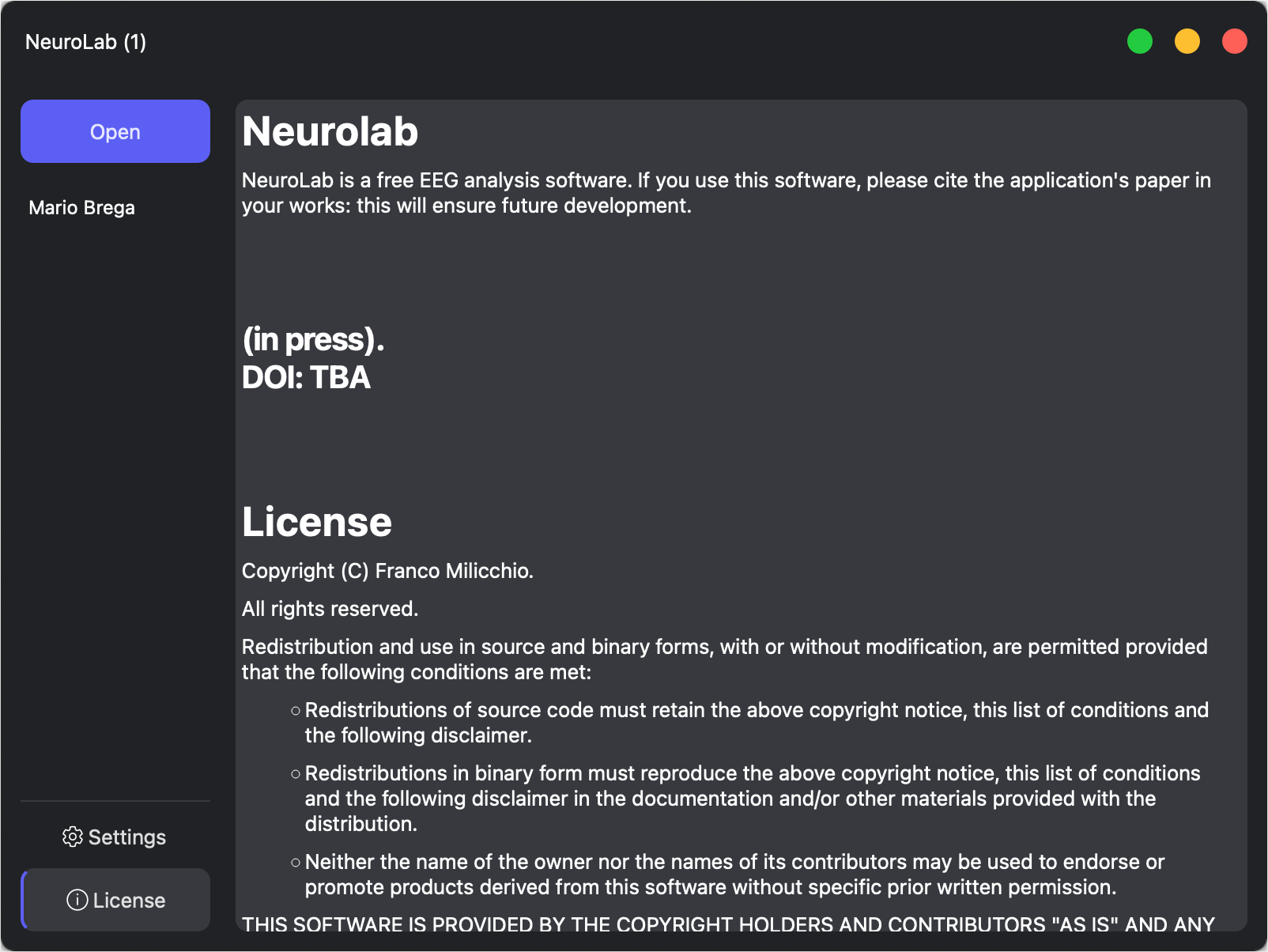
Neurolab Future
NeuroLab will be a free EEG analysis software. It will open and convert between the high-performance EE5, EDF, and Micromed's VWR. NeuroLab will be free and open source.
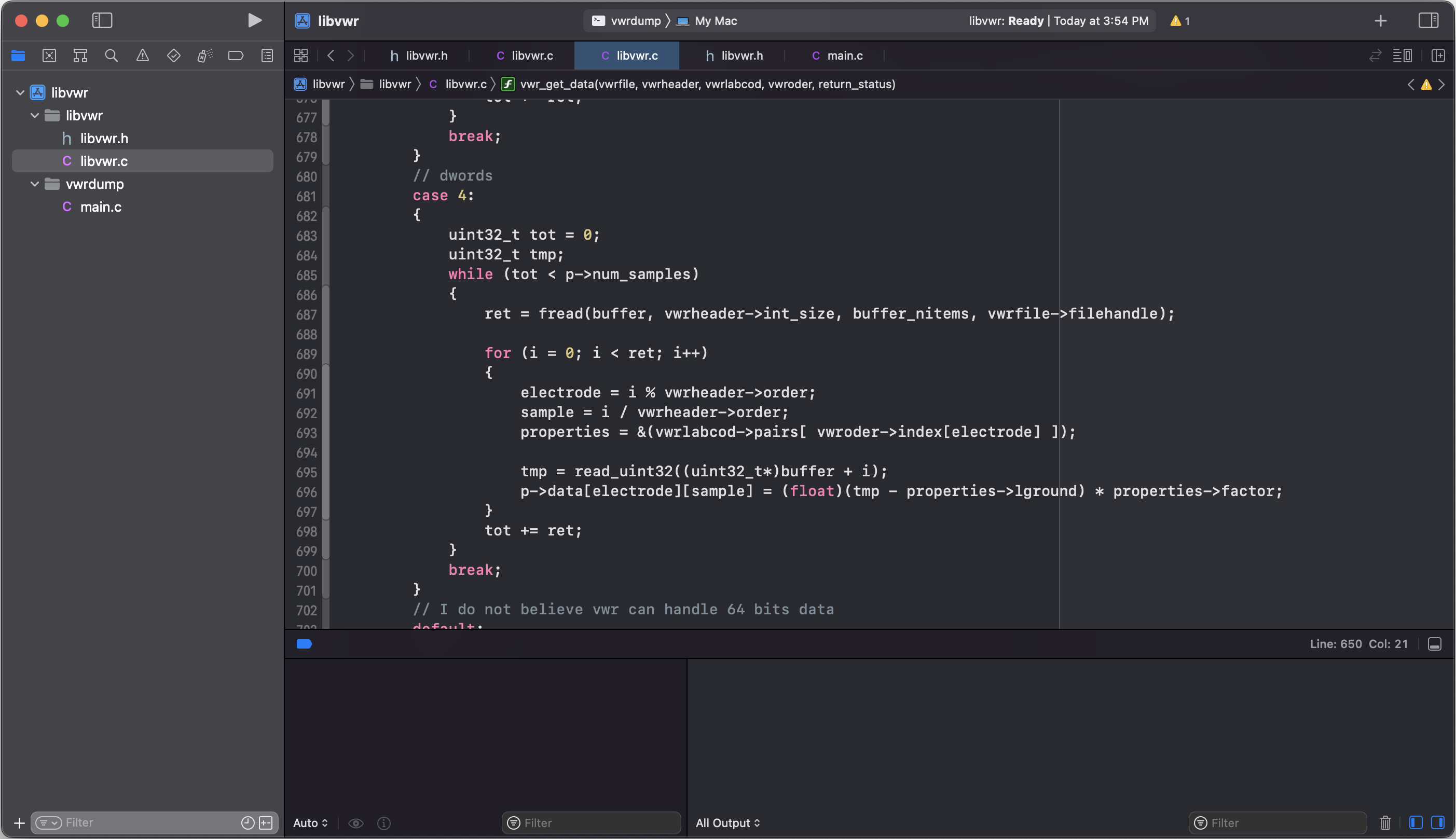
VWR Library
Micromed's VWR is a proprietary binary file format for EEG recordings. It can store also other types of time-dependent data series (e.g., ECG).
The libvwr library is a documented and open source software library written in ISO C capable of handling Micromed's VWR, a binary proprietary file format for EEGs.
This library is the result of reverse engineering Micromed's binaries along with their SystemViewer98 executable for Microsoft Windows.
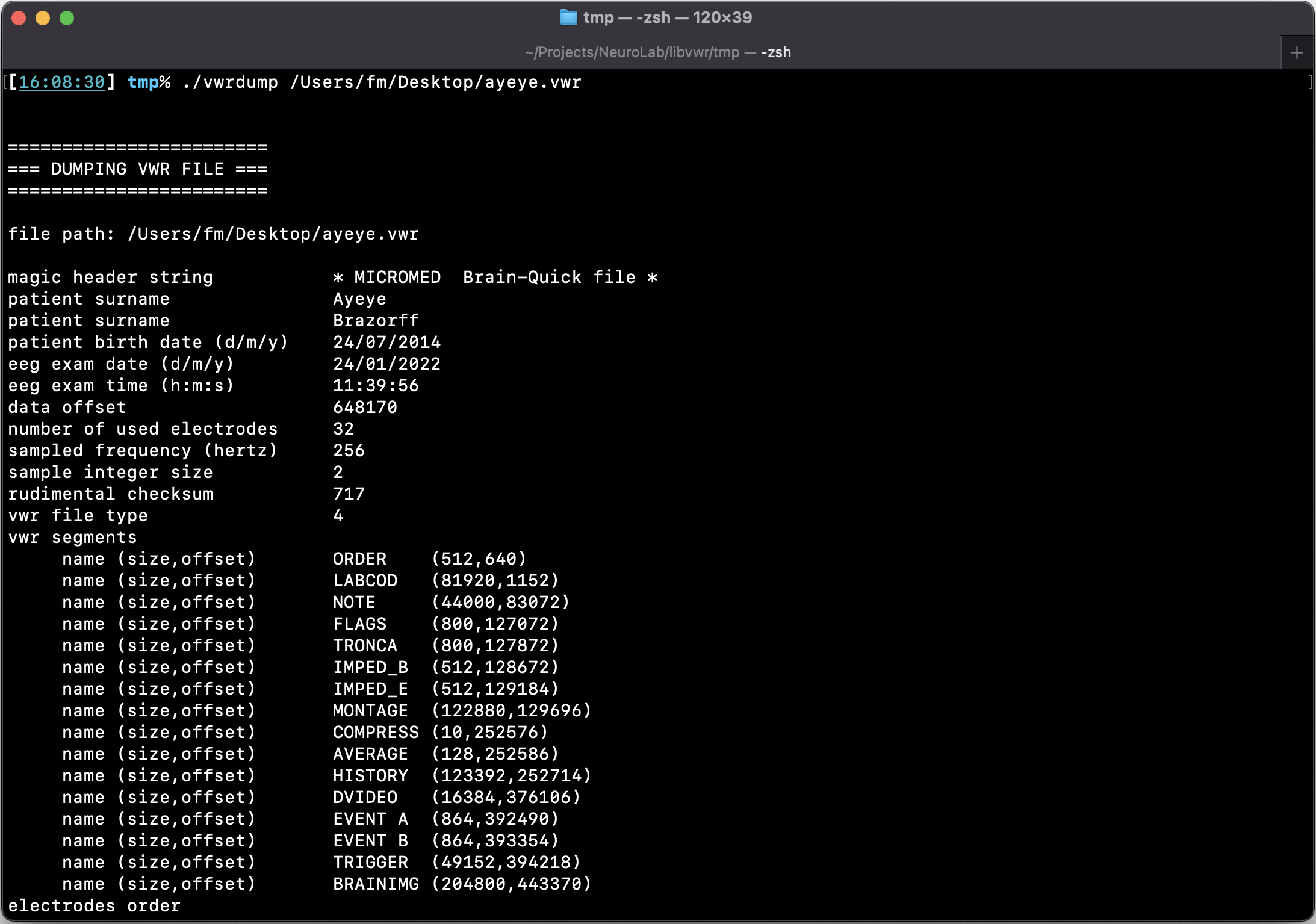
VWR Dump
The libvwr library is shipped with an application, vwrdump. This is a terminal-based program that given a VWR file, dumps all its contents in textual form, ready to be analyzed by your preferred application (Matlab, Mathematica, even Excel).
— Let's begin the journey —
A First Look
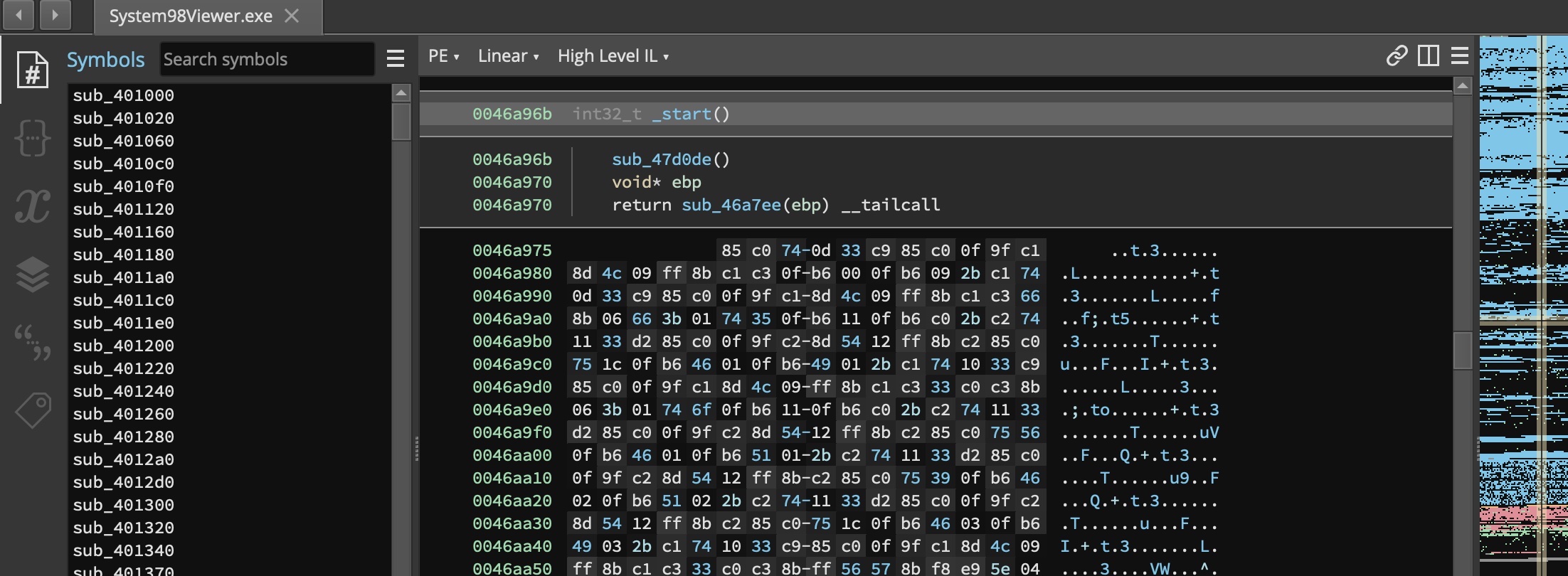
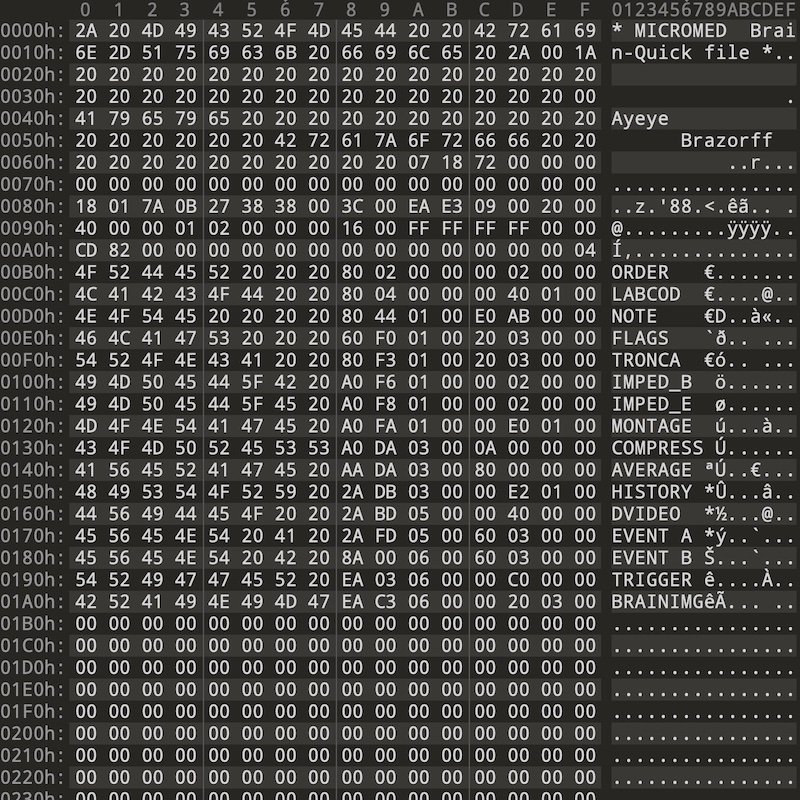
The first thing to do is to take a look at the binary file. I had used the fantastic 010 Editor from SweetScape Software Inc. This hex editor has two great features: first, you can write a template to parse structures and binary data, and second, it's free for 30 days. This meant that I could not indulge in procrastinating. At first glance, we have as expected a header, with the clear name of the patient (here a fake one), other binary encoded stuff, and a list of sections (ORDER, LABCOD, ...).
The first bytes here are clearly a header, and it brings back memories of what I did back in the early 1990s. As you can see, the header starts with a human readable string, whose length is as one can see, 32 bytes. First we have 30 bytes, an ASCII string, followed by 0x00 0x1A.
Old DOS Times
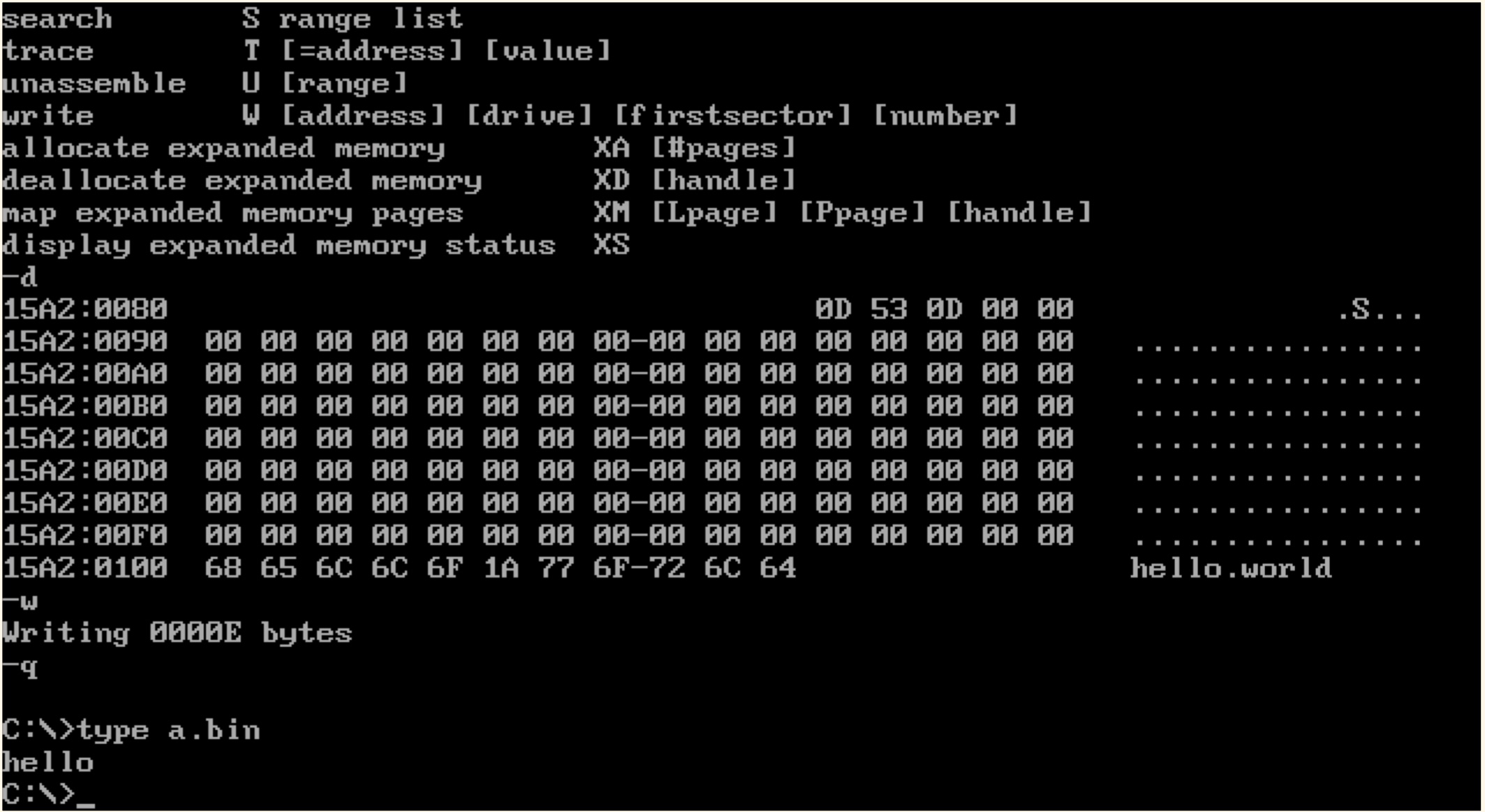
I know that sequence. Back in the MS-DOS days, I used to block users to dump the contents of my files in the command prompt. You issued type filename.ext to get the contents of a file, and the hex 0x1A was handled by COMMAND.COM as EOF, the end-of-file character.
As a proof, you can see in the image how it worked (still works?). I have created a file and with the DEBUG.EXE (the MS-DOS assembler included in MS-DOS) assembled DB "hello", 1a, "world", and the contents after the 0x1a byte won't show. It was a neat trick with binary files, they won't pollute the prompt. Try that yourself online!
SystemViewer98
Now we can skip the binary blob after the name, and take a look at the sections. Each section, for instance ORDER, is constituted by an 8 bytes ASCII string (the section name), followed by 8 bytes. As we are facing the SystemViewer98 executable, a 32-bit Win32 API binary, those 8 bytes must be read as 2 DWORDs, a 32 bits offset and 32 bits for the section size. It is highly unlikely that they implemented a 64 bit arithmetic by hand.
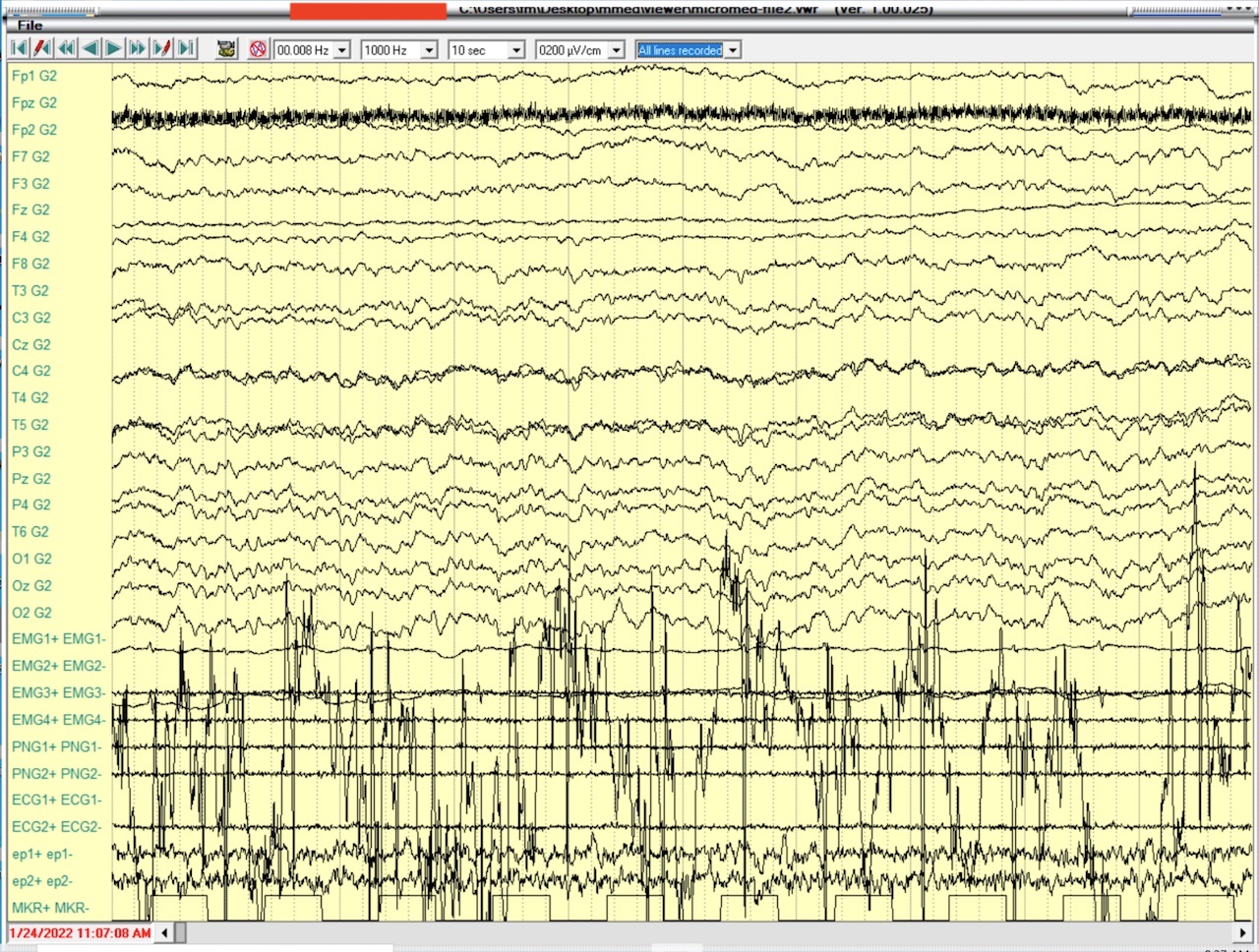
The first step is to see what the application sees. As you can see, we have a very basic layout, with the EEG, the legend (the electrodes pair). The application has few controls, which I will replicate in my viewer, and a preset on which electrode pairs to display. The preset is just for the end user that can select different pairs, and all the original pairs recorded is called a montage, I've been told. Let's take a look at where I can find the pairs in the VWR.
Montage
And here's the first weirdness: the number of electrode pairs is way too long. There are more pairs in the file that are not, apparently, present in the file.
00000480 00 00 47 32 00 00 00 00 47 32 00 00 00 00 00 00 |..G2....G2......| 00000490 00 00 ff ff 00 00 00 80 00 00 80 f3 ff ff 80 0c |................| 000004a0 00 00 00 00 96 00 00 00 00 00 00 00 01 00 80 00 |................| 000004b0 00 00 00 00 00 00 00 00 00 01 00 00 00 00 00 00 |................| 000004c0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 000004e0 00 00 00 00 00 00 00 00 80 f3 ff ff 80 0c 00 00 |................| 000004f0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| 00000500 01 00 46 70 31 00 00 00 47 32 00 00 00 00 00 00 |..Fp1...G2......| 00000510 00 00 ff ff 00 00 00 80 00 00 80 f3 ff ff 80 0c |................| [...] 00000fe0 00 00 00 00 00 00 00 00 80 f3 ff ff 80 0c 00 00 |................| 00000ff0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| 00001000 00 00 41 31 00 00 00 00 47 32 00 00 00 00 00 00 |..A1....G2......| 00001010 00 00 ff ff 00 00 00 80 00 00 80 f3 ff ff 80 0c |................|
Events
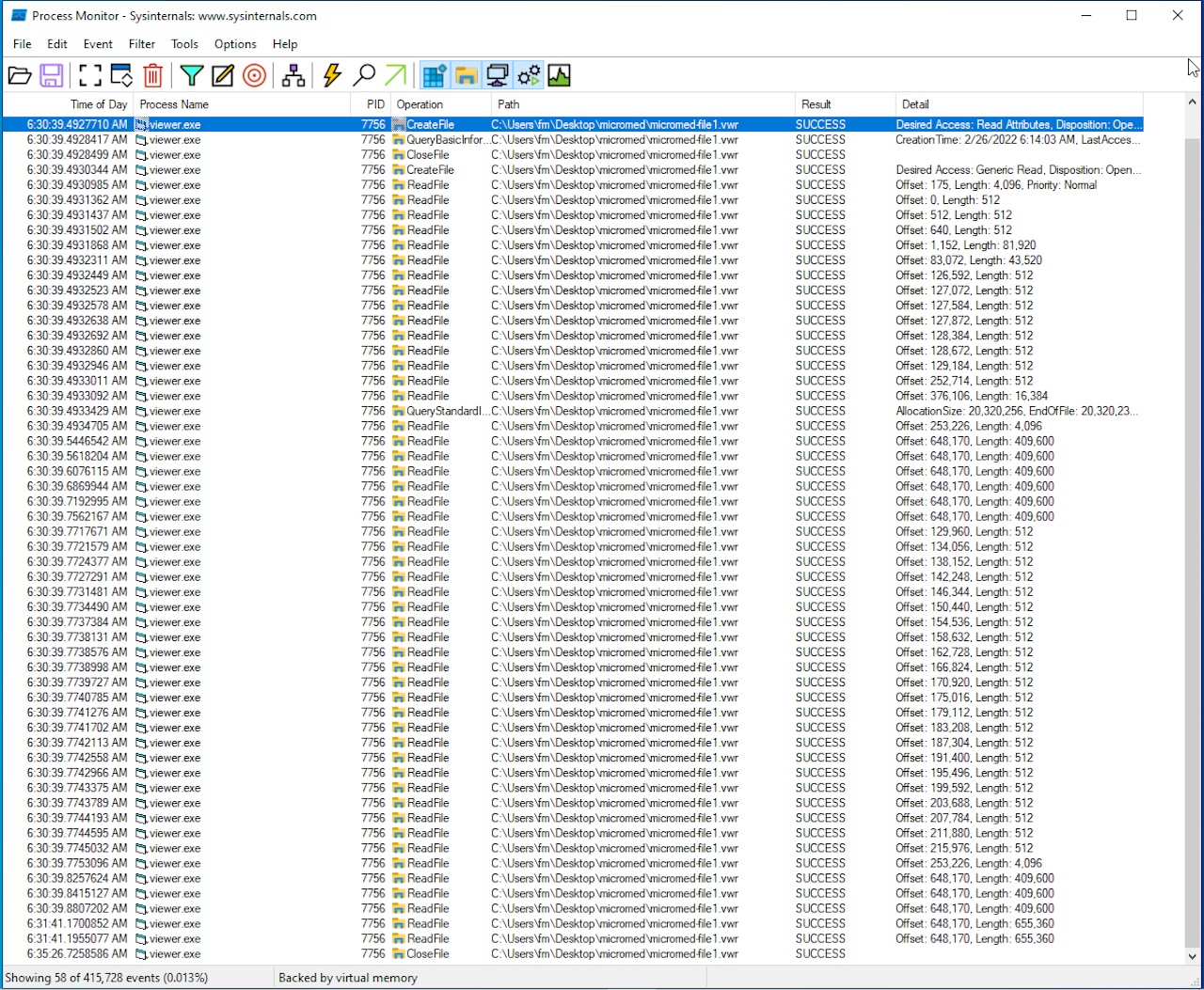
Let's fire up Process Monitor to see where to start. If I can see how the program behaves when opening a VWR file I will get a starting point. But be aware that Process Monitor will show every event, so it's advisable to setup a filter. In this case, the easiest filter is to include every event containing "VWR", case insensitively.
So here we are, and we see that the application finds the given file, checks for read permissions, and weirdly enough, it will not read the file from the beginning.
Thanks to this, I know where the entry point of the read function inside the executable is: it must be a fseek call with 175 offset, then it will read something important. Note that you cannot rely on the read length, as it will be buffered by the OS.
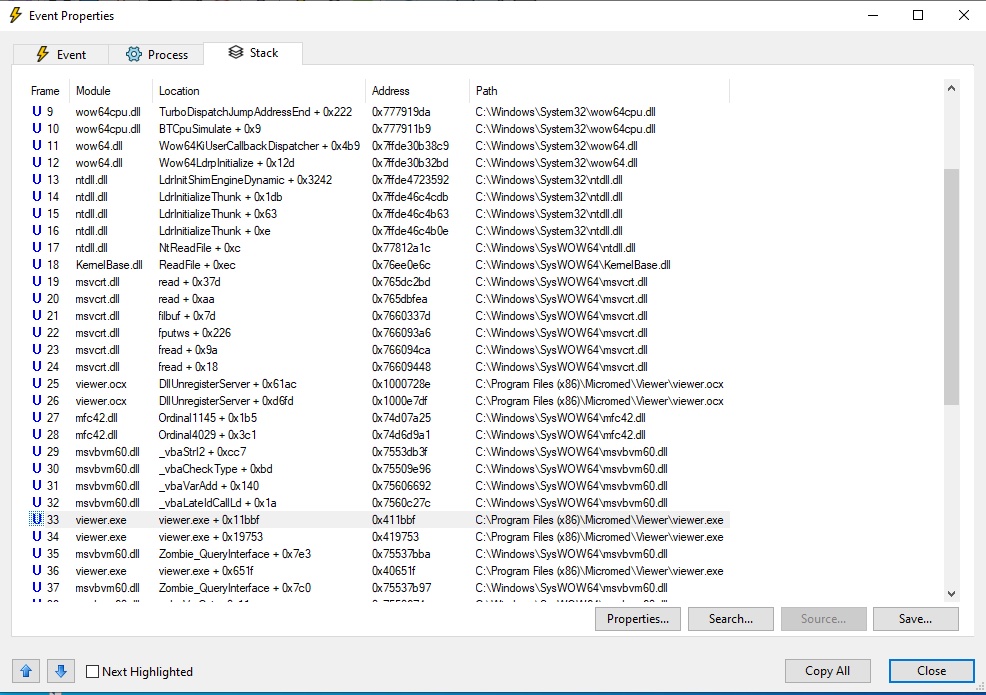
The OCX
Finding the offset it's easy, just look for fseek calls, and this can be easily done with Binary Ninja by Vector 35, a very nice free (for some minutes at time) disassembler. But the search was unsuccessful.
The package from Micromed contains some files, other than the executable. One in particular is an OCX file, an OLE Control Extension for Microsoft Windows. At first I thought they've implemented the viewer (the graphic display of the signals) in the OCX, but apparently it does more.
Looking at the stack trace of the read in the image, we can see that it's the OCX that manages everything. And lo and behold, we have our entry point.
File Seek
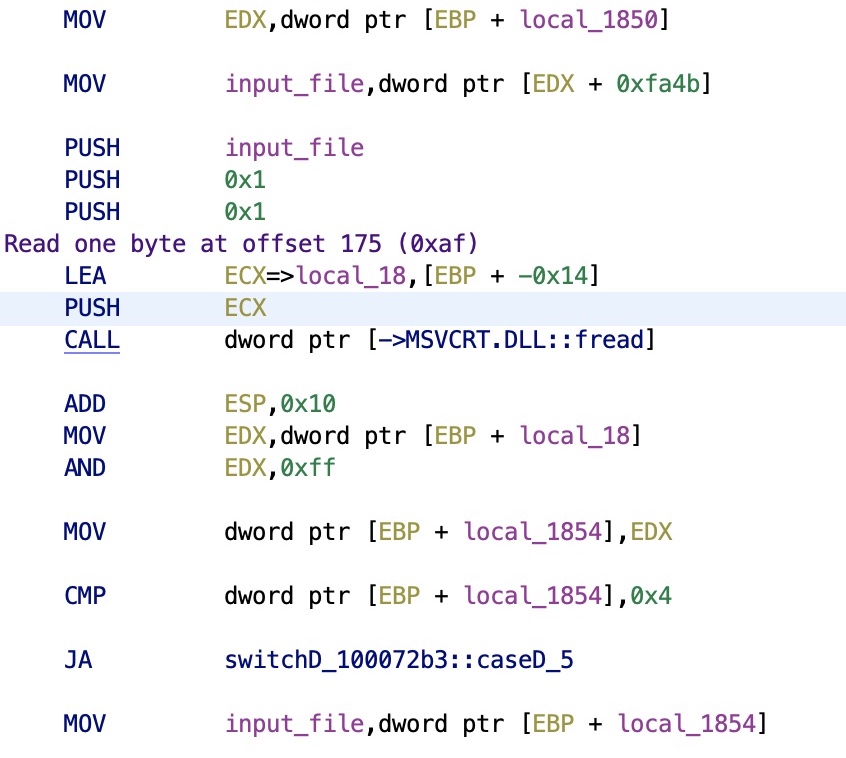
After rewording some variables, you end up with the real code. As you can see we have 175, or 0xaf, being pushed to the stack, followed by what is clearly the second parameter of the fseek routine: the file handle. So now we have the file handle: offset 0xfa4b.
10007258 68 af 00 PUSH 0xaf
00 00
1000725d 8b 85 b4 MOV input_file,dword ptr [EBP + local_1850]
e7 ff ff
10007263 8b 88 4b MOV ECX,dword ptr [input_file + 0xfa4b]
fa 00 00
10007269 51 PUSH ECX
1000726a ff 15 94 CALL dword ptr [->MSVCRT.DLL::fseek]
24 01 10
File Types
Here's the surprise. At offset 175 we're just before the list of sections (ORDER, LABCOD, ...), off by one byte. And it reads exactly one byte. But here's the surprise: a VWR is not a single file format, but they have versions, for the lack of a better word. All the files I have have this byte set to 0x04. I'll proceed only in this direction, using the IDA debugger, a very powerful debugger that has great versatility by Hex Rays.
As you can see from the assembly, the program now checks for this value, and it's a switch. How can you tell? Well, it's easy. Compilers usually output first the default branch, in assembly here, comparing bytes, is the JA opcode (jump if above). What about the values?
The jump values are stored in an array, for instance here we have 5 values, case 0 .. case default (== 5), so we will have an array in pseudo-C uint32_t switchD_100072b3[5] = { 0x..., 0x..., 0x..., 0x..., 0x...};, so all the computer has to do is JMP dword ptr [value + ->switchD_100072b3].

Header Buffer
The routine that reads the header gives us precious memory addresses, and more. Before you ask, what is that "input_file"? It's the first parameter of this Win32 function, it contains the global state of the OCX, which handles just one file at time. Easy to verify by opening a new file.
The address 0x11f02 is obviously the buffer, so the function will read 640 bytes in that address. Funny number, it reminds me the famous 640 KB of RAM limiting MS-DOS without HIMEM.SYS or EMM386.SYS (later an EXE).

Checks
Now things get interesting. We have several checks that are relative to the buffer, since the address checked is always 0x11f02 + offset. Let's see what they are checking.
At offset 0x11f6c we have a comparison with 0xc, in decimal is 12. It's a month! So buffer[106] is a month (0x11f6c - 0x11f02 = 106), and so is buffer[129], and then it follows quite easily that the adjacent bytes are dates. Two dates are present in the viewer, the patient's birth date and the exam's date: this is a confirmation. By checking the dates it's easy to see which is which, moreover, the exam date is followed by the time.
The VWR format uses a single byte for everything, and the year is stored as year - 1900. This should not surprise you at all, it was common practice back in the DOS days. The whole Y2K problem, however, was really overblown and wasn't that problematic at all.

Sections
Moving on with the code, we see now that we're reading now the sections, ORDER, LABCOD, and so on.
The order of fseek/fread along with the offsets show us that the binary VWR stores the section information as:
uint8_t name[8]; uint32_t offset; uint32_t size;

Data Offset
After reading the file size by fseek/ftell, the routine will check two things. Here we focus on one, the other, a funnier one, is directly below.
We can see the IDIV, the integer division opcode, used with the file_size. This indicates that we're looking for something inside the file. As I will confirm by looking at the painting routines, we're here checking the signal data offset.
We have now that the operation seen here computes file_size - buffer[138] = data size in bytes, so at that offset in the file we have the signals.

Rudimentary Checksum
The second check done in this routine is something very cute. As you can see in the picture after zeroing the ret variable (via XOR), the function will load bytes from the buffer.
When checking where in the file it reads, we know that VWR contains a rudimentary checksum for the file: the buffer[160] contains the checksum, computed as patient_surname[0] + patient_surname[1] + patient_surname[2] + patient_name[0] + patient_name[1] + patient_name[3] + patient_birth_day + patient_birth_month + patient_birth_year.
It would have been preferable to use, at that time, the CRC32 checksum, employed by all compressors like PKZIP (first release in 1989), the father of the ZIP file format (by Phil Zatz, hence the "PK").

Unit Conversion
Still I needed a unit conversion from whatever the data is, to some meaningful floating point. Fortunately, the viewer has a clear routine that paints with MFC (Microsoft Foundation Classes). I've worked with this library before in C++, it was good, but the Qt Library that I use since 1999 cannot be beaten. Especially with the documentation. In the paint routine that handles all the CPen and CDC (Device Contex class, all MFC classes start with "C"), I find a call to a peculiar function. This function returns a floating point, you can see it uses the old FPU stack-based opcodes like FILD (float integer load) or FIDIV (float integer divide). FPU is a nightmare compared to MMX/SSE/AVX.
The switch case in this function compares 0x0, 0x1, 0x2, and 0xffff, and stores a weird integer such as MOV dword ptr [EBP + local_8], 0x3f800000 for the non-initiated, that constant is in reality the floating point 1.0, and we have also 0x447a0000 = 1000, 0x49742400 = 1000000, 0x3a83126f = 0.001. Not only that, but also it converts between the data and the electrode pairs buffer. We definitely have our unit conversion.
Data Buffers
With some painstaking cross-check in the code, we arrive at the following addresses (just an excerpt, it's long):
0x11f02 = header buffer 0x11f6c = month, buffer[106] 0x11f83 = month, buffer[129] 0x11f94 = order, buffer[146] 0x1025f = file size 0xfa4b = FILE* 0x11fba = ORDER offset 0x11fbe = ORDER size 0x12182 = ORDER buffer 0x11fca = LABCOD offset 0x11fce = LABCOD size 0x12dcc = LABCOD buffer 0xf2da = NOTES offset 0xf2de = NOTES size 0xf2d2 = NOTES num items = NOTES size DIV 44 [...] 0x10263 = total number of samples 0x1202a = MONTAGES offset 0x26dcc = MONTAGES buffer
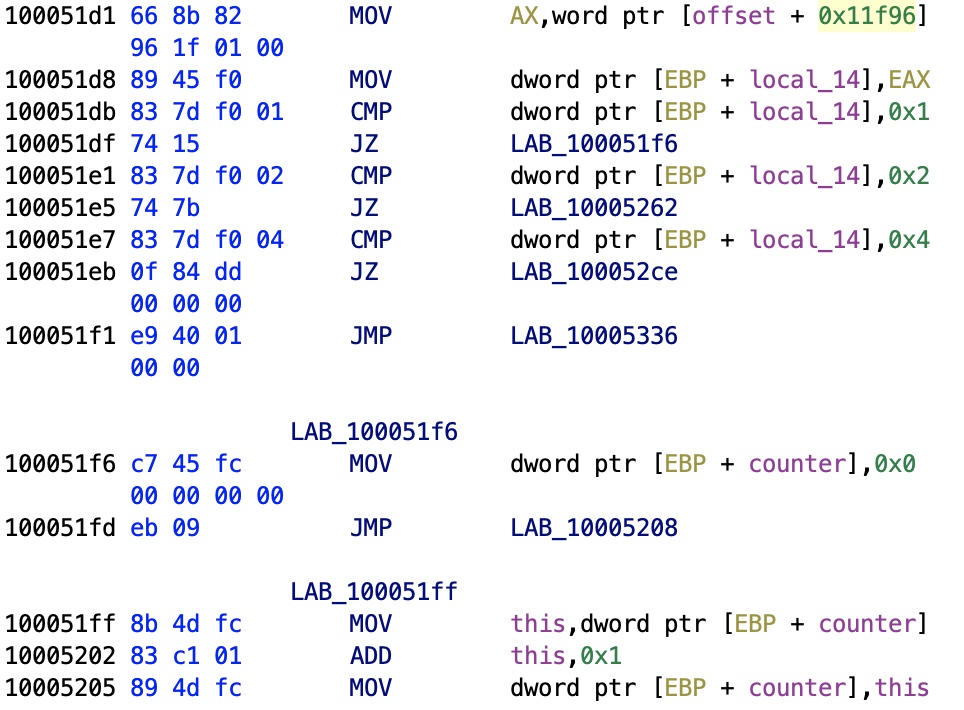
Integer Types
The routine that reads the actual data is easy to find, and reveals something interesting. The VWR file format has no fixed type for the data.
As you can see, the code compares a local stack variable, corresponding to sddress 0x11f96 to 1, 2, 4. The offset is buffer[148], and the three numbers correspond to the integer size used by the VWR encoding, obviously corresponding to uint8_t, uint16_t, and uint32_t. We have already the routine that gives us floats, here we have the input.

Electrodes
After some time dumping on screen, I now know how things work in a VWR, as you can see from the image of an EEG electrode signal.
The LABCOD contains all possible pairs of electrodes, with their boundaries (logical and physical, as I have discovered by reading a book on EEG analysis). The ORDER section contains the actual montage, the electrodes pairs that were recorded with their numbers referring to LABCOD. NOTES contain brief texts that doctors may record regarding any event that occurred during the EEG exam (for instance "The patient sneezed", or "Moves the head"). In my files many other sections (e.g., FLAGS, TRONCA, IMPED_B, EVENT_A) were garbage, while MONTAGE contains presets that doctors want to see, subsets of electrode pairs: this is not interesting to me, as I will develop my own viewer, as you can see below.
Conclusion
Now the VWR data format is known, and I developed a library in ISO C, libvwr, along with the vwrdump tool that takes a VWR file and dumps the contents I have described above to a CSV file.
I've chosen ISO C to maximize the interoperability with other languages, for instance Dart/Flutter. This proved to be a failure for performance reasons. I need to display approximately 1.5M samples per electrode pairs, with an average of 20 pairs. Flutter was painfully slow with just one signal constituted by 100K samples. That is why I am developing the viewer NeuroLab in C++ with the Qt Library, it's really fast, and portable on every platform.
How long did it take? The 010 Editor has a 30 days free trial, and I reverse engineered the viewer in 4 weeks. I worked for two hours on Saturday and Sunday, except the last week when I worked only on Saturday. That makes 14 hours more or less.
It was fun, really.